1 本节介绍
📝本节您将学习如何通过庐山派来注册并识别特定的人脸,如无特殊说明,以后所有例程的显示设备均为通过外接立创·3.1寸屏幕扩展板,在3.1寸小屏幕上显示。若用户无3.1寸屏幕扩展板也可以正常在IDE的缓冲区,只是受限于USB带宽,可能会帧率较低或卡顿。
🏆学习目标
1️⃣如何用庐山派开发板去注册人脸信息,存储到TF卡里。
2️⃣如何去识别特定的人脸,检测当前人脸特征并与上一步中保存的特征进行匹配识别。
庐山派开发板的固件是存储在TF中的,模型文件已经提前写入到固件中了,所以大家只需要复制下面的代码到IDE,传递到开发板上就可以正常运行了。无需再额外拷贝,至于后面需要拷贝自己训练的模型那就是后话了。
传统的人脸识别通常需要通过PC或服务器运算,而随着边缘AI芯片与嵌入式平台的兴起,很多智能终端都可以在本地执行人脸检测与识别算法。同时嘉楠官方也提供了对应的模型和库文件。
人脸识别注册最常见的应用场景就是人脸门禁或者打卡机了,之前的例程都是去识别任意人脸。想要去识别特定的人脸,就需要先将你想要识别的人脸注册到系统里,然后再去运行识别的程序。
2 代码例程
2.1 基本流程
人脸检测: 首先使用人脸检测模型从输入的图像流中定位人脸的区域、边界框以及五官关键点(比如眼睛、鼻子、嘴巴的位置)。
人脸特征提取: 在获得人脸关键点位置后,对人脸进行仿射校正对齐标准五官位置,并使用人脸特征提取模型将对齐后的人脸提取为固定长度的特征向量。
人脸特征注册: 将提取到的人脸特征向量存入本地数据库(其实就是我们运行固件用的TF卡)。通过数据库文件名或其他标识就可以和这个此特征对应的人名(也就是注册时的ID)关联。
人脸识别: 识别阶段会对输入帧中的人脸同数据库中存储的特征进行相似度计算。若相似度超过一定阈值(在本例中为0.75),则判断为数据库中某已知人员;否则输出“unknown”。
本章节内容是有两个程序的,第一个是人脸注册(涵盖前三个步骤1,2,3),第二个是人脸识别,其实就是人脸特征的注册和识别。
需要注意的是,在本章中,人脸特征的注册并不是通过摄像头获取图像来注册的,而是通过往CanMV设备中存放对应人脸照片,然后运行注册人脸特征的程序去读取这个人脸照片并生成对应的人脸特征bin文件,放入固定的目录中。而人脸识别就是运行人脸识别的程序通过摄像头获取图像并提取人脸特征和上一个程序保存的人脸特征bin文件进行对比计算。
2.2 人脸注册
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import image
import aidemo
import random
import gc
import sys
import math
# 自定义人脸检测任务类
class FaceDetApp(AIBase):
def __init__(self,kmodel_path,model_input_size,anchors,confidence_threshold=0.25,nms_threshold=0.3,rgb888p_size=[1280,720],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
# kmodel路径
self.kmodel_path=kmodel_path
# 检测模型输入分辨率
self.model_input_size=model_input_size
# 置信度阈值
self.confidence_threshold=confidence_threshold
# nms阈值
self.nms_threshold=nms_threshold
self.anchors=anchors
# sensor给到AI的图像分辨率,宽16字节对齐
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
# 视频输出VO分辨率,宽16字节对齐
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
# debug模式
self.debug_mode=debug_mode
# 实例化Ai2d,用于实现模型预处理
self.ai2d=Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
self.image_size=[]
# 配置预处理操作,这里使用了pad和resize,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/app/libs/AI2D.py查看
def config_preprocess(self,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
# 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,可以通过设置input_image_size自行修改输入尺寸
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
self.image_size=[input_image_size[1],input_image_size[0]]
# 计算padding参数,并设置padding预处理
self.ai2d.pad(self.get_pad_param(ai2d_input_size), 0, [104,117,123])
# 设置resize预处理
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# 构建预处理流程,参数为预处理输入tensor的shape和预处理输出的tensor的shape
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义后处理,results是模型输出的array列表,这里使用了aidemo库的face_det_post_process接口
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
res = aidemo.face_det_post_process(self.confidence_threshold,self.nms_threshold,self.model_input_size[0],self.anchors,self.image_size,results)
if len(res)==0:
return res
else:
return res[0],res[1]
def get_pad_param(self,image_input_size):
dst_w = self.model_input_size[0]
dst_h = self.model_input_size[1]
# 计算最小的缩放比例,等比例缩放
ratio_w = dst_w / image_input_size[0]
ratio_h = dst_h / image_input_size[1]
if ratio_w < ratio_h:
ratio = ratio_w
else:
ratio = ratio_h
new_w = (int)(ratio * image_input_size[0])
new_h = (int)(ratio * image_input_size[1])
dw = (dst_w - new_w) / 2
dh = (dst_h - new_h) / 2
top = (int)(round(0))
bottom = (int)(round(dh * 2 + 0.1))
left = (int)(round(0))
right = (int)(round(dw * 2 - 0.1))
return [0,0,0,0,top, bottom, left, right]
# 自定义人脸注册任务类
class FaceRegistrationApp(AIBase):
def __init__(self,kmodel_path,model_input_size,rgb888p_size=[1920,1080],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
# kmodel路径
self.kmodel_path=kmodel_path
# 人脸注册模型输入分辨率
self.model_input_size=model_input_size
# sensor给到AI的图像分辨率,宽16字节对齐
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
# 视频输出VO分辨率,宽16字节对齐
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
# debug模式
self.debug_mode=debug_mode
# 标准5官
self.umeyama_args_112 = [
38.2946 , 51.6963 ,
73.5318 , 51.5014 ,
56.0252 , 71.7366 ,
41.5493 , 92.3655 ,
70.7299 , 92.2041
]
self.ai2d=Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
# 配置预处理操作,这里使用了affine,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/app/libs/AI2D.py查看
def config_preprocess(self,landm,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
# 计算affine矩阵,并设置仿射变换预处理
affine_matrix = self.get_affine_matrix(landm)
self.ai2d.affine(nn.interp_method.cv2_bilinear,0, 0, 127, 1,affine_matrix)
# 构建预处理流程,参数为预处理输入tensor的shape和预处理输出的tensor的shape
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义后处理
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
return results[0][0]
def svd22(self,a):
# svd
s = [0.0, 0.0]
u = [0.0, 0.0, 0.0, 0.0]
v = [0.0, 0.0, 0.0, 0.0]
s[0] = (math.sqrt((a[0] - a[3]) ** 2 + (a[1] + a[2]) ** 2) + math.sqrt((a[0] + a[3]) ** 2 + (a[1] - a[2]) ** 2)) / 2
s[1] = abs(s[0] - math.sqrt((a[0] - a[3]) ** 2 + (a[1] + a[2]) ** 2))
v[2] = math.sin((math.atan2(2 * (a[0] * a[1] + a[2] * a[3]), a[0] ** 2 - a[1] ** 2 + a[2] ** 2 - a[3] ** 2)) / 2) if \
s[0] > s[1] else 0
v[0] = math.sqrt(1 - v[2] ** 2)
v[1] = -v[2]
v[3] = v[0]
u[0] = -(a[0] * v[0] + a[1] * v[2]) / s[0] if s[0] != 0 else 1
u[2] = -(a[2] * v[0] + a[3] * v[2]) / s[0] if s[0] != 0 else 0
u[1] = (a[0] * v[1] + a[1] * v[3]) / s[1] if s[1] != 0 else -u[2]
u[3] = (a[2] * v[1] + a[3] * v[3]) / s[1] if s[1] != 0 else u[0]
v[0] = -v[0]
v[2] = -v[2]
return u, s, v
def image_umeyama_112(self,src):
# 使用Umeyama算法计算仿射变换矩阵
SRC_NUM = 5
SRC_DIM = 2
src_mean = [0.0, 0.0]
dst_mean = [0.0, 0.0]
for i in range(0,SRC_NUM * 2,2):
src_mean[0] += src[i]
src_mean[1] += src[i + 1]
dst_mean[0] += self.umeyama_args_112[i]
dst_mean[1] += self.umeyama_args_112[i + 1]
src_mean[0] /= SRC_NUM
src_mean[1] /= SRC_NUM
dst_mean[0] /= SRC_NUM
dst_mean[1] /= SRC_NUM
src_demean = [[0.0, 0.0] for _ in range(SRC_NUM)]
dst_demean = [[0.0, 0.0] for _ in range(SRC_NUM)]
for i in range(SRC_NUM):
src_demean[i][0] = src[2 * i] - src_mean[0]
src_demean[i][1] = src[2 * i + 1] - src_mean[1]
dst_demean[i][0] = self.umeyama_args_112[2 * i] - dst_mean[0]
dst_demean[i][1] = self.umeyama_args_112[2 * i + 1] - dst_mean[1]
A = [[0.0, 0.0], [0.0, 0.0]]
for i in range(SRC_DIM):
for k in range(SRC_DIM):
for j in range(SRC_NUM):
A[i][k] += dst_demean[j][i] * src_demean[j][k]
A[i][k] /= SRC_NUM
T = [[1, 0, 0], [0, 1, 0], [0, 0, 1]]
U, S, V = self.svd22([A[0][0], A[0][1], A[1][0], A[1][1]])
T[0][0] = U[0] * V[0] + U[1] * V[2]
T[0][1] = U[0] * V[1] + U[1] * V[3]
T[1][0] = U[2] * V[0] + U[3] * V[2]
T[1][1] = U[2] * V[1] + U[3] * V[3]
scale = 1.0
src_demean_mean = [0.0, 0.0]
src_demean_var = [0.0, 0.0]
for i in range(SRC_NUM):
src_demean_mean[0] += src_demean[i][0]
src_demean_mean[1] += src_demean[i][1]
src_demean_mean[0] /= SRC_NUM
src_demean_mean[1] /= SRC_NUM
for i in range(SRC_NUM):
src_demean_var[0] += (src_demean_mean[0] - src_demean[i][0]) * (src_demean_mean[0] - src_demean[i][0])
src_demean_var[1] += (src_demean_mean[1] - src_demean[i][1]) * (src_demean_mean[1] - src_demean[i][1])
src_demean_var[0] /= SRC_NUM
src_demean_var[1] /= SRC_NUM
scale = 1.0 / (src_demean_var[0] + src_demean_var[1]) * (S[0] + S[1])
T[0][2] = dst_mean[0] - scale * (T[0][0] * src_mean[0] + T[0][1] * src_mean[1])
T[1][2] = dst_mean[1] - scale * (T[1][0] * src_mean[0] + T[1][1] * src_mean[1])
T[0][0] *= scale
T[0][1] *= scale
T[1][0] *= scale
T[1][1] *= scale
return T
def get_affine_matrix(self,sparse_points):
# 获取affine变换矩阵
with ScopedTiming("get_affine_matrix", self.debug_mode > 1):
# 使用Umeyama算法计算仿射变换矩阵
matrix_dst = self.image_umeyama_112(sparse_points)
matrix_dst = [matrix_dst[0][0],matrix_dst[0][1],matrix_dst[0][2],
matrix_dst[1][0],matrix_dst[1][1],matrix_dst[1][2]]
return matrix_dst
# 人脸注册任务类
class FaceRegistration:
def __init__(self,face_det_kmodel,face_reg_kmodel,det_input_size,reg_input_size,database_dir,anchors,confidence_threshold=0.25,nms_threshold=0.3,rgb888p_size=[1280,720],display_size=[1920,1080],debug_mode=0):
# 人脸检测模型路径
self.face_det_kmodel=face_det_kmodel
# 人脸注册模型路径
self.face_reg_kmodel=face_reg_kmodel
# 人脸检测模型输入分辨率
self.det_input_size=det_input_size
# 人脸注册模型输入分辨率
self.reg_input_size=reg_input_size
self.database_dir=database_dir
# anchors
self.anchors=anchors
# 置信度阈值
self.confidence_threshold=confidence_threshold
# nms阈值
self.nms_threshold=nms_threshold
# sensor给到AI的图像分辨率,宽16字节对齐
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
# 视频输出VO分辨率,宽16字节对齐
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
# debug_mode模式
self.debug_mode=debug_mode
self.face_det=FaceDetApp(self.face_det_kmodel,model_input_size=self.det_input_size,anchors=self.anchors,confidence_threshold=self.confidence_threshold,nms_threshold=self.nms_threshold,debug_mode=0)
self.face_reg=FaceRegistrationApp(self.face_reg_kmodel,model_input_size=self.reg_input_size,rgb888p_size=self.rgb888p_size)
# run函数
def run(self,input_np,img_file):
self.face_det.config_preprocess(input_image_size=[input_np.shape[3],input_np.shape[2]])
det_boxes,landms=self.face_det.run(input_np)
if det_boxes:
if det_boxes.shape[0] == 1:
# 若是只检测到一张人脸,则将该人脸注册到数据库
db_i_name = img_file.split('.')[0]
for landm in landms:
self.face_reg.config_preprocess(landm,input_image_size=[input_np.shape[3],input_np.shape[2]])
reg_result = self.face_reg.run(input_np)
with open(self.database_dir+'{}.bin'.format(db_i_name), "wb") as file:
file.write(reg_result.tobytes())
print('Success!')
else:
print('Only one person in a picture when you sign up')
else:
print('No person detected')
def image2rgb888array(self,img): #4维
# 将Image转换为rgb888格式
with ScopedTiming("fr_kpu_deinit",self.debug_mode > 0):
img_data_rgb888=img.to_rgb888()
# hwc,rgb888
img_hwc=img_data_rgb888.to_numpy_ref()
shape=img_hwc.shape
img_tmp = img_hwc.reshape((shape[0] * shape[1], shape[2]))
img_tmp_trans = img_tmp.transpose()
img_res=img_tmp_trans.copy()
# chw,rgb888
img_return=img_res.reshape((1,shape[2],shape[0],shape[1]))
return img_return
if __name__=="__main__":
# 人脸检测模型路径
face_det_kmodel_path="/sdcard/examples/kmodel/face_detection_320.kmodel"
# 人脸注册模型路径
face_reg_kmodel_path="/sdcard/examples/kmodel/face_recognition.kmodel"
# 其它参数
anchors_path="/sdcard/examples/utils/prior_data_320.bin"
database_dir="/sdcard/examples/utils/db/"
database_img_dir="/sdcard/examples/utils/db_img/"
face_det_input_size=[320,320]
face_reg_input_size=[112,112]
confidence_threshold=0.5
nms_threshold=0.2
anchor_len=4200
det_dim=4
anchors = np.fromfile(anchors_path, dtype=np.float)
anchors = anchors.reshape((anchor_len,det_dim))
max_register_face = 100 #数据库最多人脸个数
feature_num = 128 #人脸识别特征维度
fr=FaceRegistration(face_det_kmodel_path,face_reg_kmodel_path,det_input_size=face_det_input_size,reg_input_size=face_reg_input_size,database_dir=database_dir,anchors=anchors,confidence_threshold=confidence_threshold,nms_threshold=nms_threshold)
try:
# 获取图像列表
img_list = os.listdir(database_img_dir)
for img_file in img_list:
#本地读取一张图像
full_img_file = database_img_dir + img_file
print(full_img_file)
img = image.Image(full_img_file)
img.compress_for_ide()
# 转rgb888的chw格式
rgb888p_img_ndarry = fr.image2rgb888array(img)
# 人脸注册
fr.run(rgb888p_img_ndarry,img_file)
gc.collect()
except Exception as e:
sys.print_exception(e)
finally:
fr.face_det.deinit()
fr.face_reg.deinit()在执行以上代码前,需在database_img_dir目录也就是CanmV IDE目录(/sdcard/examples/utils/db_img/)中放置待注册人脸的图像文件。代码运行后会对该目录下的所有图像逐张进行人脸检测,如果检测到且仅有一张人脸(如果一张图片里有两张脸庐山派也不知道到底是谁啊),那就提取其特征向量并以.bin文件的形式存入database_dir目录中也就是CanmV IDE目录(/sdcard/examples/utils/db/)。文件名会和我们的原图像文件名对应,比如我这里放入的图片是a.png,那么对应的数据库二进制文件就是a.bin。
上面程序的主要流程如下:
- 加载人脸检测模型
face_detection_320.kmodel和人脸特征提取模型face_recognition.kmodel。 - 然后对图片进行预处理、检测,若有且仅有一张人脸则提取特征并存储。
- 如果检测不到人脸或者检测到多张人脸则提示错误信息,若对应的图片能正常检测到有且只有一张人脸则会正常运行并在IDE的串行终端处打印
Success!,同时对这些待注册的人脸进行特征提取。 - 如果以上都正常运行的话就会在
/sdcard/examples/utils/db/目录下生成对应的.bin特征文件。
2.3 人脸检测识别
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import image
import aidemo
import random
import gc
import sys
import math
# 自定义人脸检测任务类
class FaceDetApp(AIBase):
def __init__(self,kmodel_path,model_input_size,anchors,confidence_threshold=0.25,nms_threshold=0.3,rgb888p_size=[1920,1080],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
# kmodel路径
self.kmodel_path=kmodel_path
# 检测模型输入分辨率
self.model_input_size=model_input_size
# 置信度阈值
self.confidence_threshold=confidence_threshold
# nms阈值
self.nms_threshold=nms_threshold
self.anchors=anchors
# sensor给到AI的图像分辨率,宽16字节对齐
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
# 视频输出VO分辨率,宽16字节对齐
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
# debug模式
self.debug_mode=debug_mode
# 实例化Ai2d,用于实现模型预处理
self.ai2d=Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
# 配置预处理操作,这里使用了pad和resize,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/app/libs/AI2D.py查看
def config_preprocess(self,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
# 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,可以通过设置input_image_size自行修改输入尺寸
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
# 计算padding参数,并设置padding预处理
self.ai2d.pad(self.get_pad_param(), 0, [104,117,123])
# 设置resize预处理
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# 构建预处理流程,参数为预处理输入tensor的shape和预处理输出的tensor的shape
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义后处理,results是模型输出的array列表,这里使用了aidemo库的face_det_post_process接口
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
res = aidemo.face_det_post_process(self.confidence_threshold,self.nms_threshold,self.model_input_size[0],self.anchors,self.rgb888p_size,results)
if len(res)==0:
return res,res
else:
return res[0],res[1]
def get_pad_param(self):
dst_w = self.model_input_size[0]
dst_h = self.model_input_size[1]
# 计算最小的缩放比例,等比例缩放
ratio_w = dst_w / self.rgb888p_size[0]
ratio_h = dst_h / self.rgb888p_size[1]
if ratio_w < ratio_h:
ratio = ratio_w
else:
ratio = ratio_h
new_w = (int)(ratio * self.rgb888p_size[0])
new_h = (int)(ratio * self.rgb888p_size[1])
dw = (dst_w - new_w) / 2
dh = (dst_h - new_h) / 2
top = (int)(round(0))
bottom = (int)(round(dh * 2 + 0.1))
left = (int)(round(0))
right = (int)(round(dw * 2 - 0.1))
return [0,0,0,0,top, bottom, left, right]
# 自定义人脸注册任务类
class FaceRegistrationApp(AIBase):
def __init__(self,kmodel_path,model_input_size,rgb888p_size=[1920,1080],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
# kmodel路径
self.kmodel_path=kmodel_path
# 检测模型输入分辨率
self.model_input_size=model_input_size
# sensor给到AI的图像分辨率,宽16字节对齐
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
# 视频输出VO分辨率,宽16字节对齐
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
# debug模式
self.debug_mode=debug_mode
# 标准5官
self.umeyama_args_112 = [
38.2946 , 51.6963 ,
73.5318 , 51.5014 ,
56.0252 , 71.7366 ,
41.5493 , 92.3655 ,
70.7299 , 92.2041
]
self.ai2d=Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
# 配置预处理操作,这里使用了affine,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/app/libs/AI2D.py查看
def config_preprocess(self,landm,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
# 计算affine矩阵,并设置仿射变换预处理
affine_matrix = self.get_affine_matrix(landm)
self.ai2d.affine(nn.interp_method.cv2_bilinear,0, 0, 127, 1,affine_matrix)
# 构建预处理流程,参数为预处理输入tensor的shape和预处理输出的tensor的shape
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义后处理
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
return results[0][0]
def svd22(self,a):
# svd
s = [0.0, 0.0]
u = [0.0, 0.0, 0.0, 0.0]
v = [0.0, 0.0, 0.0, 0.0]
s[0] = (math.sqrt((a[0] - a[3]) ** 2 + (a[1] + a[2]) ** 2) + math.sqrt((a[0] + a[3]) ** 2 + (a[1] - a[2]) ** 2)) / 2
s[1] = abs(s[0] - math.sqrt((a[0] - a[3]) ** 2 + (a[1] + a[2]) ** 2))
v[2] = math.sin((math.atan2(2 * (a[0] * a[1] + a[2] * a[3]), a[0] ** 2 - a[1] ** 2 + a[2] ** 2 - a[3] ** 2)) / 2) if \
s[0] > s[1] else 0
v[0] = math.sqrt(1 - v[2] ** 2)
v[1] = -v[2]
v[3] = v[0]
u[0] = -(a[0] * v[0] + a[1] * v[2]) / s[0] if s[0] != 0 else 1
u[2] = -(a[2] * v[0] + a[3] * v[2]) / s[0] if s[0] != 0 else 0
u[1] = (a[0] * v[1] + a[1] * v[3]) / s[1] if s[1] != 0 else -u[2]
u[3] = (a[2] * v[1] + a[3] * v[3]) / s[1] if s[1] != 0 else u[0]
v[0] = -v[0]
v[2] = -v[2]
return u, s, v
def image_umeyama_112(self,src):
# 使用Umeyama算法计算仿射变换矩阵
SRC_NUM = 5
SRC_DIM = 2
src_mean = [0.0, 0.0]
dst_mean = [0.0, 0.0]
for i in range(0,SRC_NUM * 2,2):
src_mean[0] += src[i]
src_mean[1] += src[i + 1]
dst_mean[0] += self.umeyama_args_112[i]
dst_mean[1] += self.umeyama_args_112[i + 1]
src_mean[0] /= SRC_NUM
src_mean[1] /= SRC_NUM
dst_mean[0] /= SRC_NUM
dst_mean[1] /= SRC_NUM
src_demean = [[0.0, 0.0] for _ in range(SRC_NUM)]
dst_demean = [[0.0, 0.0] for _ in range(SRC_NUM)]
for i in range(SRC_NUM):
src_demean[i][0] = src[2 * i] - src_mean[0]
src_demean[i][1] = src[2 * i + 1] - src_mean[1]
dst_demean[i][0] = self.umeyama_args_112[2 * i] - dst_mean[0]
dst_demean[i][1] = self.umeyama_args_112[2 * i + 1] - dst_mean[1]
A = [[0.0, 0.0], [0.0, 0.0]]
for i in range(SRC_DIM):
for k in range(SRC_DIM):
for j in range(SRC_NUM):
A[i][k] += dst_demean[j][i] * src_demean[j][k]
A[i][k] /= SRC_NUM
T = [[1, 0, 0], [0, 1, 0], [0, 0, 1]]
U, S, V = self.svd22([A[0][0], A[0][1], A[1][0], A[1][1]])
T[0][0] = U[0] * V[0] + U[1] * V[2]
T[0][1] = U[0] * V[1] + U[1] * V[3]
T[1][0] = U[2] * V[0] + U[3] * V[2]
T[1][1] = U[2] * V[1] + U[3] * V[3]
scale = 1.0
src_demean_mean = [0.0, 0.0]
src_demean_var = [0.0, 0.0]
for i in range(SRC_NUM):
src_demean_mean[0] += src_demean[i][0]
src_demean_mean[1] += src_demean[i][1]
src_demean_mean[0] /= SRC_NUM
src_demean_mean[1] /= SRC_NUM
for i in range(SRC_NUM):
src_demean_var[0] += (src_demean_mean[0] - src_demean[i][0]) * (src_demean_mean[0] - src_demean[i][0])
src_demean_var[1] += (src_demean_mean[1] - src_demean[i][1]) * (src_demean_mean[1] - src_demean[i][1])
src_demean_var[0] /= SRC_NUM
src_demean_var[1] /= SRC_NUM
scale = 1.0 / (src_demean_var[0] + src_demean_var[1]) * (S[0] + S[1])
T[0][2] = dst_mean[0] - scale * (T[0][0] * src_mean[0] + T[0][1] * src_mean[1])
T[1][2] = dst_mean[1] - scale * (T[1][0] * src_mean[0] + T[1][1] * src_mean[1])
T[0][0] *= scale
T[0][1] *= scale
T[1][0] *= scale
T[1][1] *= scale
return T
def get_affine_matrix(self,sparse_points):
# 获取affine变换矩阵
with ScopedTiming("get_affine_matrix", self.debug_mode > 1):
# 使用Umeyama算法计算仿射变换矩阵
matrix_dst = self.image_umeyama_112(sparse_points)
matrix_dst = [matrix_dst[0][0],matrix_dst[0][1],matrix_dst[0][2],
matrix_dst[1][0],matrix_dst[1][1],matrix_dst[1][2]]
return matrix_dst
# 人脸识别任务类
class FaceRecognition:
def __init__(self,face_det_kmodel,face_reg_kmodel,det_input_size,reg_input_size,database_dir,anchors,confidence_threshold=0.25,nms_threshold=0.3,face_recognition_threshold=0.75,rgb888p_size=[1280,720],display_size=[1920,1080],debug_mode=0):
# 人脸检测模型路径
self.face_det_kmodel=face_det_kmodel
# 人脸识别模型路径
self.face_reg_kmodel=face_reg_kmodel
# 人脸检测模型输入分辨率
self.det_input_size=det_input_size
# 人脸识别模型输入分辨率
self.reg_input_size=reg_input_size
self.database_dir=database_dir
# anchors
self.anchors=anchors
# 置信度阈值
self.confidence_threshold=confidence_threshold
# nms阈值
self.nms_threshold=nms_threshold
self.face_recognition_threshold=face_recognition_threshold
# sensor给到AI的图像分辨率,宽16字节对齐
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
# 视频输出VO分辨率,宽16字节对齐
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
# debug_mode模式
self.debug_mode=debug_mode
self.max_register_face = 100 # 数据库最多人脸个数
self.feature_num = 128 # 人脸识别特征维度
self.valid_register_face = 0 # 已注册人脸数
self.db_name= []
self.db_data= []
self.face_det=FaceDetApp(self.face_det_kmodel,model_input_size=self.det_input_size,anchors=self.anchors,confidence_threshold=self.confidence_threshold,nms_threshold=self.nms_threshold,rgb888p_size=self.rgb888p_size,display_size=self.display_size,debug_mode=0)
self.face_reg=FaceRegistrationApp(self.face_reg_kmodel,model_input_size=self.reg_input_size,rgb888p_size=self.rgb888p_size,display_size=self.display_size)
self.face_det.config_preprocess()
# 人脸数据库初始化
self.database_init()
# run函数
def run(self,input_np):
# 执行人脸检测
det_boxes,landms=self.face_det.run(input_np)
recg_res = []
for landm in landms:
# 针对每个人脸五官点,推理得到人脸特征,并计算特征在数据库中相似度
self.face_reg.config_preprocess(landm)
feature=self.face_reg.run(input_np)
res = self.database_search(feature)
recg_res.append(res)
return det_boxes,recg_res
def database_init(self):
# 数据初始化,构建数据库人名列表和数据库特征列表
with ScopedTiming("database_init", self.debug_mode > 1):
db_file_list = os.listdir(self.database_dir)
for db_file in db_file_list:
if not db_file.endswith('.bin'):
continue
if self.valid_register_face >= self.max_register_face:
break
valid_index = self.valid_register_face
full_db_file = self.database_dir + db_file
with open(full_db_file, 'rb') as f:
data = f.read()
feature = np.frombuffer(data, dtype=np.float)
self.db_data.append(feature)
name = db_file.split('.')[0]
self.db_name.append(name)
self.valid_register_face += 1
def database_reset(self):
# 数据库清空
with ScopedTiming("database_reset", self.debug_mode > 1):
print("database clearing...")
self.db_name = []
self.db_data = []
self.valid_register_face = 0
print("database clear Done!")
def database_search(self,feature):
# 数据库查询
with ScopedTiming("database_search", self.debug_mode > 1):
v_id = -1
v_score_max = 0.0
# 将当前人脸特征归一化
feature /= np.linalg.norm(feature)
# 遍历当前人脸数据库,统计最高得分
for i in range(self.valid_register_face):
db_feature = self.db_data[i]
db_feature /= np.linalg.norm(db_feature)
# 计算数据库特征与当前人脸特征相似度
v_score = np.dot(feature, db_feature)/2 + 0.5
if v_score > v_score_max:
v_score_max = v_score
v_id = i
if v_id == -1:
# 数据库中无人脸
return 'unknown'
elif v_score_max < self.face_recognition_threshold:
# 小于人脸识别阈值,未识别
return 'unknown'
else:
# 识别成功
result = 'name: {}, score:{}'.format(self.db_name[v_id],v_score_max)
return result
# 绘制识别结果
def draw_result(self,pl,dets,recg_results):
pl.osd_img.clear()
if dets:
for i,det in enumerate(dets):
# (1)画人脸框
x1, y1, w, h = map(lambda x: int(round(x, 0)), det[:4])
x1 = x1 * self.display_size[0]//self.rgb888p_size[0]
y1 = y1 * self.display_size[1]//self.rgb888p_size[1]
w = w * self.display_size[0]//self.rgb888p_size[0]
h = h * self.display_size[1]//self.rgb888p_size[1]
pl.osd_img.draw_rectangle(x1,y1, w, h, color=(255,0, 0, 255), thickness = 4)
# (2)写人脸识别结果
recg_text = recg_results[i]
pl.osd_img.draw_string_advanced(x1,y1,32,recg_text,color=(255, 255, 0, 0))
if __name__=="__main__":
# 注意:执行人脸识别任务之前,需要先执行人脸注册任务进行人脸身份注册生成feature数据库
# 显示模式,默认"hdmi",可以选择"hdmi"和"lcd"
display_mode="lcd"
# k230保持不变,k230d可调整为[640,360]
rgb888p_size = [1920, 1080]
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
# 人脸检测模型路径
face_det_kmodel_path="/sdcard/examples/kmodel/face_detection_320.kmodel"
# 人脸识别模型路径
face_reg_kmodel_path="/sdcard/examples/kmodel/face_recognition.kmodel"
# 其它参数
anchors_path="/sdcard/examples/utils/prior_data_320.bin"
database_dir ="/sdcard/examples/utils/db/"
face_det_input_size=[320,320]
face_reg_input_size=[112,112]
confidence_threshold=0.5
nms_threshold=0.2
anchor_len=4200
det_dim=4
anchors = np.fromfile(anchors_path, dtype=np.float)
anchors = anchors.reshape((anchor_len,det_dim))
face_recognition_threshold = 0.75 # 人脸识别阈值
# 初始化PipeLine,只关注传给AI的图像分辨率,显示的分辨率
pl=PipeLine(rgb888p_size=rgb888p_size,display_size=display_size,display_mode=display_mode)
pl.create()
fr=FaceRecognition(face_det_kmodel_path,face_reg_kmodel_path,det_input_size=face_det_input_size,reg_input_size=face_reg_input_size,database_dir=database_dir,anchors=anchors,confidence_threshold=confidence_threshold,nms_threshold=nms_threshold,face_recognition_threshold=face_recognition_threshold,rgb888p_size=rgb888p_size,display_size=display_size)
try:
while True:
os.exitpoint()
with ScopedTiming("total", 1):
img=pl.get_frame() # 获取当前帧
det_boxes,recg_res=fr.run(img) # 推理当前帧
fr.draw_result(pl,det_boxes,recg_res) # 绘制推理结果
pl.show_image() # 展示推理效果
gc.collect()
except Exception as e:
sys.print_exception(e)
finally:
fr.face_det.deinit()
fr.face_reg.deinit()
pl.destroy()在运行上面的人脸注册程序后,我们就可以运行这个人脸检测识别的程序了。该程序可以对输入的视频流(来自默认摄像头CSI2)进行检测识别了。
注意!
在运行该程序前一定要先确保运行2.2的【人脸注册】程序,并在庐山派设备的/sdcard/examples/utils/db/目录中已生成对应的.bin特征文件。
这个程序的主要流程如下:
- 通过PipleLine模块获取两路视频流,一路直接给到显示层【显示路径】,一路用于给KPU进行推理【推理路径】。我们推理过后的结果最终是叠加在显示视频流上面的。
- 用人脸检测模型识别当前帧中的人脸框与关键点。
- 对识别到的人脸进行特征提取。
- 将提取到的特征与数据库中的已有的特征(就是在上个程序中存储到
/sdcard/examples/utils/db/目录中的.bin特征文件)进行相似度匹配,若超过设定阈值(在本例中是0.75)则显示对应文件名,否则就显示“unknown”。
3 实际运行
3.1 注册人脸信息
首先我们运行第一个程序,就是上面的人脸注册程序,首先把以下三张图片另存到本地,并把名字分别命名为a,b,c。



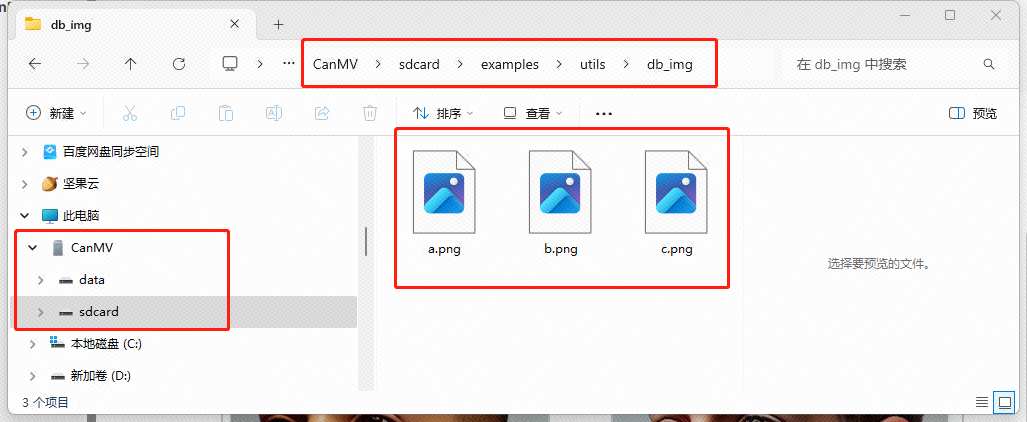
将人脸注册程序复制到IDE中运行:
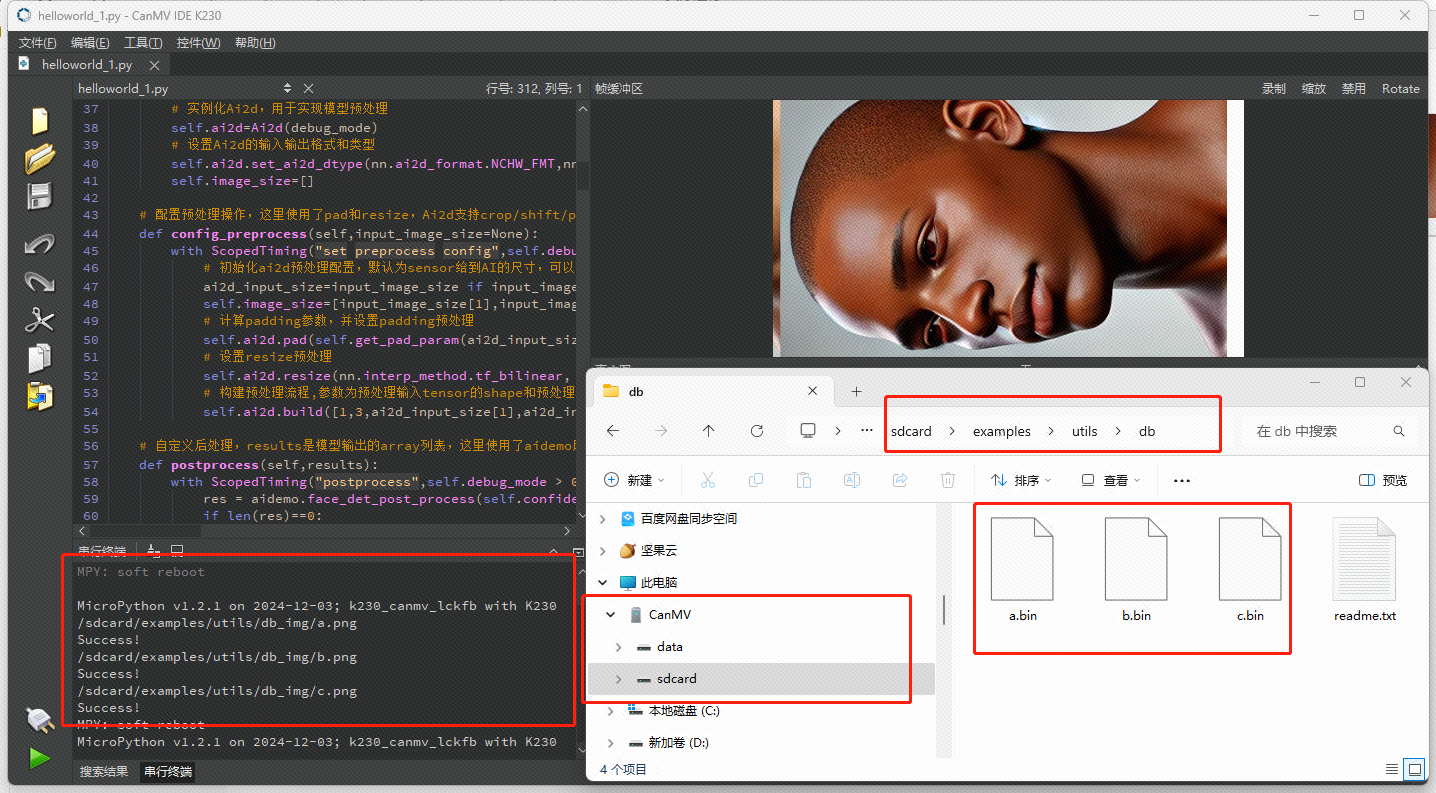
如果之前操作都正常,在运行过程中,IDE的帧缓冲区就会显示我们需要注册的那张图片,同时CanMV IDE K230的的串行终端也会打印三个Success!,代表我们放入的三个图片的人脸特征都被正常注册了,此时打开CanMV设备的/sdcard/examples/utils/db/目录(如果你已经在程序运行前打开,那就需要刷新一下当前这个文件夹了),也可以看到特征文件也被正常生成了,会在后面的程序中用到,如果这里没有bin文件,那就不要再进行下一步了,从头来过吧!
3.2 识别人脸信息
运行第二个程序【人脸检测识别】,将至复制到IDE中运行,效果如下:
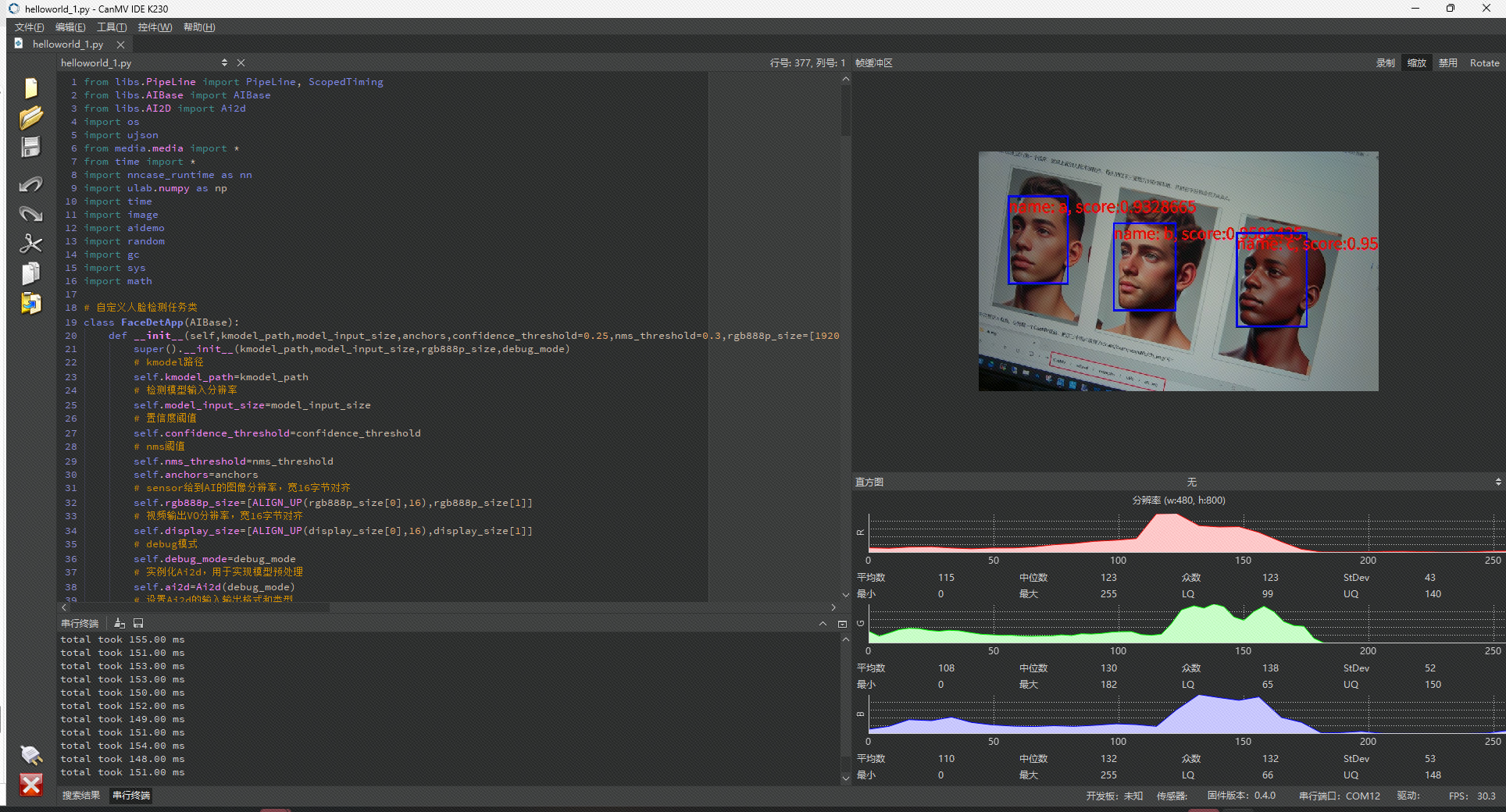
注意
在识别时要庐山派的TYPE-C口朝上,识别效果才好。如果需要各个方向的识别效果都优秀,可能需要在特征提取时多下些功夫。